

If your Fluentd configuration file hasn't changed but you're noticing ingestion delays, you should first verify that the Fluentd is actually receiving more logs than before. Here is the query you can use to confirm it.
(tag='logVolume' metric='logBytes' !(k8s-cluster=*)) $forlogfile contains "/fluentd/"
You should substitute $forlogfile contains "/fluentd/"if your Fluentd logs are named differently. Submitting the query and checking the graph to verify that the ingestion delay time aligns with the spike in log volume (ex. the below screenshot shows the spike in Fluentd log volume from 9/4 7 AM).
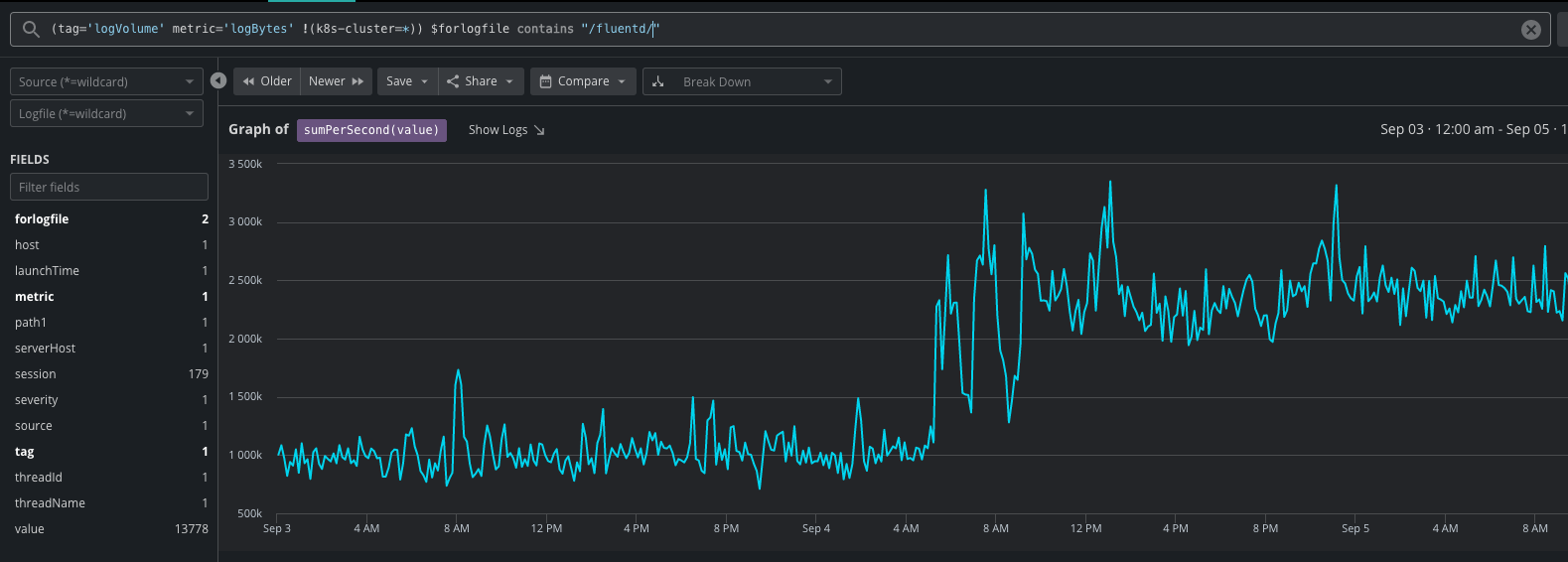
Once it's confirmed, you should review your Fluentd config file to see if there are changes that can be made to mitigate the problem.
In the above example, the Fluentd ingestion log volume was around 0.5 MB/s, but it has increased to over 3MB/s since 9/4. We know that our new Fluentd connector can now accept 6MB/s of data ingestion comparing to 1MB/s in the prior infrastructure, so this issue can be resolved by increasing the chunk_limit_size and max_request_buffer to 4MB and 5.9MB.
<store>
@type scalyr api_write_token "#{ENV['SCALYR_TOKEN']}"
max_request_buffer 5900000
</store>
<buffer>
chunk_limit_size 4MB
flush_interval 5s
overflow_action throw_exception retry_forever true
retry_type periodic
retry_wait 5s
</buffer>
Applying the above config enables the Fluentd to handle the peak traffic in my environment. You can also apply the same process to troubleshoot the Fluentd ingestion issue.
Please refer to our Fluentd documentation for more information:
https://github.com/scalyr/scalyr-fluentd
https://app.scalyr.com/solutions/fluentd
Comments
0 comments
Please sign in to leave a comment.